この記事は公立はこだて未来大学 Advent Calendar 2022 part3の9日目の記事です。
昨日は
- Part1でAtriaさんの手を振ったら部屋の電気を消す魔法が欲しい
- Part2でᎷᏫᏟᎻᎨさんの一般情報系学生向け就活体験録
- Part3でまりもbotさんのGPAロンダリング!(リンク不明)
でした!
今日2022/12/09日は、公立はこだて未来大学の2023年度学校推薦型選抜の合格発表日らしいです。自分は昨年度(2022年度)の学校推薦型選抜の合格者の一人で、懐かしいなーと思ったりしていました。(参考)
ちょうどPart3で空いている日があったので、ゆるーいネタを書こうと思います。
Twitterの話
この記事を仮に新入生(予定)の人が読んでいるとすれば、多分TwitterかAdventarを辿ってくるしかないと思うのですが(このサイトはGoogleのクロール対象ではないため)、どうでしょう?
広く知られている通り、公立はこだて未来大学はTwitter上での人の繋がりが強く、それは一般には不思議がられるほどでもあります。
こういうのとか
はこだて未来大学の一部の学生は何故氏名ではなく、Twitter上の名前で呼び合... - Yahoo!知恵袋 https://t.co/AN6xzkdR0Y
— ツナチキン☃🍀 (@seachicken_fun) November 24, 2022
はこだて未来大学の一部の学生は何故氏名ではなく、Twitter上の名前で呼び合うのでしょうか? - Yahoo!知恵袋
アイコン、大事だよねってやつ
まあTwitter上の名前で呼び合うというのはさておき、SNSの第一印象は普通に大事だと思います。
大学では 莠コ髢薙i縺励″繧ゅ� が多種多様な人間のコスプレをしていますが、その実、中身は美少女だったり美男子だったり、かわいい猫だったり犬だったりします。
すでに美少女であったり猫/犬などであったりする人は気にしなくていいですが、そうでない人もいますよね。
まずは簡単にアイコンから変わってみるのはいかがでしょう?
課題
美少女アイコンというのは意外と難しいもので、具体的には以下のような問題があります
- 自分の気に入った画像をアイコンにするのは難しい (主に著作権など)
- 絵が描ければいい感じのアイコンができるかもしれないけど、描けないとキツイ
などなどがあります(他にもあるにはあるんですが、アドベントカレンダーに書く内容か?と言われると不適切かもしれないので省きました)。
絵を描いてもらえばいいという解決方法はありますが(むしろ理想的ですが)、今回は、ちょっと前までかなり話題になっていた画像生成AIの力を借りてみることにします。 画像生成AIであれば、上の問題は解決できます(1つ目はちょっと怪しいんですが)。
世の中にはいろいろ似たようなサービスがあって、Picrewなどは、なんか良い意味でも悪い意味でも人に刺さるアイコンフォーマットの画像を作れます。それぞれのメーカーについて、そのメーカーを作った人(メーカーのメーカーであるところのsupar makerですね)が利用規約を書いてくれているはずなので、それを読みましょう。こういう一般の人が書いた利用規約というのはテンプレートを使って書かれているはずですが、結構コーナーケースを踏みやすいので、商用利用不可とだけ書かれていてもアイコンに使ったりするのは避けたほうがいいと思っています。
画像生成AI、その古今
この記事ではGANとか、AIのモデルとかそういう理論的な話は一切しないのでよろしくおねがいします(もし必要ならPart 3の枠がまだ開いてるのでだれか書いてください)。
画像生成AIといえば、ここ半年で大きな話題になったくらいのイメージかもしれませんが、実際には2, 3年くらい前から普通に存在しています。
有名所でいえばWaifuLabsであったり、Crypkoなどがあります。
これらのサービスは企業が計算資源を持っていて、その計算資源の上で計算された画像をユーザーが利用できるというものでした。その一方で、Stable Diffusionというシステムが公開され、こちらはユーザーの計算資源上で利用できるものになっています。さらにStable Diffusionに食わせるモデルをユーザーが自由に変更できるようになっているため、別のモデルを持ってくれば、全く違った画像を生成できるようになる点もポイントが高いです。
自分のTwitterアカウントの画像(下)は10ヶ月ほど前にWaifuLabsで生成した画像の一つですが、今でも気に入っています。

美少女になろう
一般的な未来大学生なら家にVRAMが8GB以上あるGPUを搭載した計算資源を持っているはずです。まだ入学していない新入生(予定)の人でも、この時期に合格が決まっているあたり、持っている可能性は高いと思っています。(AMDのGPUだといろいろ成約があったり使えなかったりするらしいです。すいません…)
もし持っていない場合は、それこそWaifuLabsやNovelAIの力を借りると良いと思います。
持っている場合は、早速stable diffusion webuiを使ってみましょう。
お好みのモデルをHugging Faceからダウンロードするのも忘れずに。最近はanything-v3や、waifu-diffusionなどを使うといいと思います。
計算資源を持っていてもgitやpythonが入っていない可能性はありますが、まあそこは頑張ってください。
stable diffusion webui - installation and runningのあたりを参考にするとよいとおもいます。Linuxの人はコマンド打つだけなので楽ですね。
知見とか
Negative Promptsについて
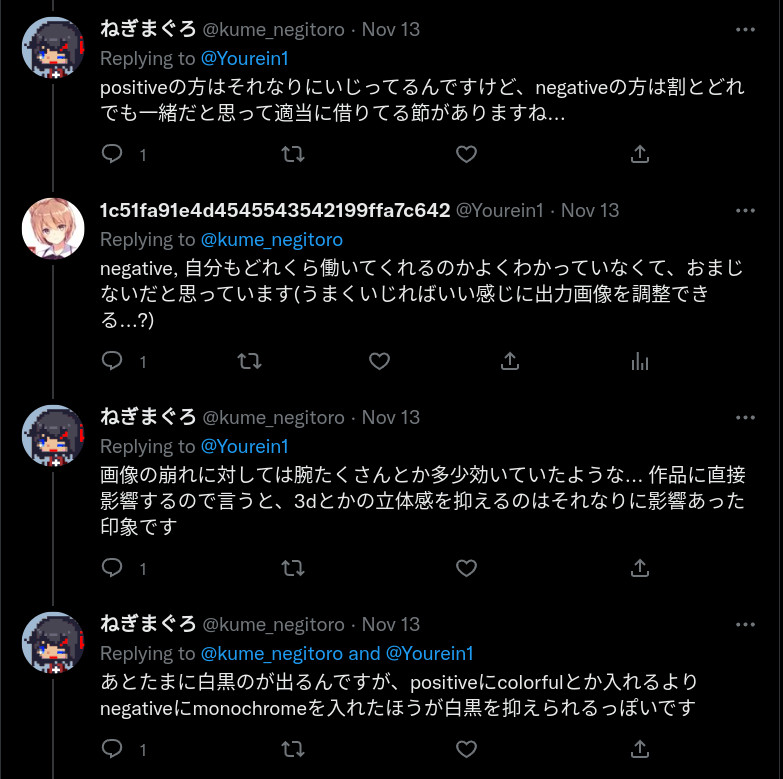
らしいです。
詠唱呪文
最初の頃、人々は「A girl that …」とかちゃんと文章を書いて画像を生成してたんですが、最近はもう詠唱呪文しかほぼほぼ使われていません。
詠唱呪文というのは、よくみる「{{masterpiece}}, 1 girl, …」みたいなやつです。
こういう詠唱呪文をまとめているサイトが世の中にはあって、有名なところでは元素法典や、NovelAI Diffusion Wiki (JP)があったりします。
しかし、詠唱呪文は共通するところはあれど、モデルが変わるとその有効性は保証できず、NovelAIで有効な呪文もAnything v3ではそこまで有効ではなかったりなどなど色々あります。(学習元のデータが異なるので、当然モデルが変わると有効性が変わるのは当たり前ですが…)
しかし、参考にはなるので、いい感じにpromptsの一部をパクって行くといいです。
CFG Scale
モデルに自分が記述したpromptsを食わせるときに、モデルにどれくらい自由裁量を持たせるかみたいな値だと解釈すればよいです。
大きければ大きいほど食わせたpromptsやimgにそった画像を生成してくる傾向にあります。
一方で、この値を下げて確率機のような遊び方をしている人もちらほら見ます。
個人的には6前後や15前後で遊ぶのが楽しくて好きです。
理論をくわしく知りたい人はこっち。
VRAM
当たり前ですが、ピクセル数の多い画像を生成するほうが使用するVRAM量は多くなります。
自分が使っているRTX3060tiはVRAMが8GBなので、あまりピクセル数の多い画像を生成するわけにはいきません。
そこで、5XX x 10XXくらいのサイズにしてBatch countを10とかにして試行回数を稼いでいます。
ここらへんはVRAMの使用量見ながら調整するとよさそう。
画像サイズ
一応webuiから画像のアップスケールができるような機能がありますが、Windowsを使っているなら普通にWaifu2x-caffeを使ったほうがいいと思います。Linuxならwaifu2x-ncnn-vulkanとか。
生成した画像の名前
生成した画像の名前は基本的にseed値が先頭に来るので、時系列順に並ぶとは限りません。
時系列順に並びたければファイルマネージャーの表示順を日付の昇順ソートにすればいいですが、画像閲覧用のソフトではその順番で読み込まれないので、いい感じに名前をつけると良いです。
WindowsならPowershellから
Get-ChildItem dir
でファイルオブジェクトを持ってきて、それをパイプして
ForEach-Object {
hoge
}
とかでうまくやれます。
詳しくはここみるといいかも
なんか難しそうだけど、WebUIにそういう名前の設定があるような気もする。というかありそう。よく見ていません。すいません…
おわり
うまぴょい
明日は
- Part1でTADA Teruki (多田 瑛貴)くんでほぼ知らん技術だけで30日間Web開発デスマーチ
- Part2でふぁるさんの「バーチャルリアリティ技術者」という資格について書きます。
- Part3でberuさんのなんか書く(内容未定)+就活爆死談
です!
Part1では明日から2日間、自分の同期(1年生)が記事を書いてくれるみたいです。楽しみに待ちましょう👀